2014-02-03
I was at Fosdem 2014. I experienced some things which may count as learning, or just exclamations. I'm not really sure how this kind of thing works. (editor's note: I guess, having written it, that the term is "braindump")
- Reproducible Builds for Debian: 65% of the archive can be reproduced from binaries we have available.
readdir() is a great source of entropy; timestamps are a great source of source-control noise. Maybe we should make a vcs-give-me-a-version for people to use instead of $(date). We're heavily dependent upon old binaries, and on toolchains that will never be audited. We trust debian developers to upload a binary that matches their source(??!).
- Shenandoah GC: Non-gc threads can do useful gc work, by copying stuff off the dead bits of heap onto live bits during writes. "Brooks pointers"(?) are a formalisation of that kind of store-and-forward kind of model in a atomic-compare-and-exchange world. People build non-generational garbage collectors but apparently this is silly and always abandoned. Concurrency without locking is hilarious. 8mb sub-heaps are cool.
- Sage is a nice bundle of
ipython --notebook and loads of maths libraries, and a magic cloud thing, but demos are hard, and nearly any audience is going to respond better to notebook (yes that's really what it looks like when you're editing it) than the command-line. Also, it was annoyingly broken on Android Chrome.
- SPARK 2014: Extending Ada to have the compiler check asserts; e.g. ensuring you never get bounds checks, cool and perfectly sensible; looked like they hadn't quite made it as automatic as I'd've hoped for Ada, which I chose to assume was a sensible language. Additionally: Let's stop unit testing trivial stuff, and let the compiler show that it's correct. Some great slides (which I can't find, yet) on how to layer your testing infrastructure when you have a competent compiler and devs who can tell it how to be happy.
- Scaling Dovecot: Nice overview of threads, clients, handoff, etc. in a world where you're expecting long-running IMAP connections (instead of the HTTP/REST nonsense I generally think about), and an overview of their load-balancing infrastructure which sounded pretty ... unique, rings of machines, rings of rings, ...
- Motivations for MAGEEC: Why and how we should care about optimising for power; changing compiler optimisation cost models for power usage (instead of instruction length or expected speed). Pretty heatmaps showing power usage across instructions, e.g. sometimes it uses less power (but is slower) to do operation on 32-bit units instead of 8-bit, etc. Proposed a performance test framework (programming competition?!) targeting "total joules" instead of "code length" or "time".
- FOSDEM wifi: Defaulting to ipv6, and how to configure bind/etc. to make people able to access the ipv4 bits of the internet. Massive shock seeing getting a reverse-dns response for an ipv6 address with a work hostname in. Big (yeah, big) discussion with anyone who would listen about why DNSSEC and this didn't or couldn't be resolved, which was eventually laid to rest by Muz. Android does its wonderful wifi-reboot-loop if presented with wifi without ipv4 connectivity. mosh doesn't support ipv6 yet.
- Autovectorisation in LLVM: LLVM is flexible enough to deal with loads of people having a stab at things. Cost models are hard, especially when they're across instruction boundaries and dependent on what the CPU is currently doing (none of the vectorisers do this right now). It's hard to keep the right amount of information available when you're running much later in the compiler, although if it was in the original source then it's fine. They're heavily dependent on inlining. I wish Java was better at inlining. It seems to fix everything.
- Avatar, running analysis tools on embedded stuff: Let's just pause for a moment here and look at this:
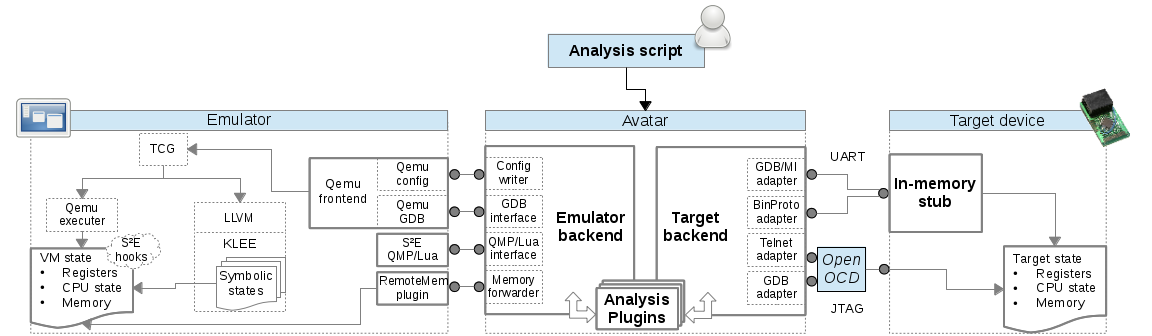
Wow. It's some kind of black magic for running a huge binary blob that they don't have the code nor the toolchain for both on the real hardware and on an emulator and kind of syncing all of it backwards and forwards over python3 and multiple different connectors and multiple gdbs writing random memory editors into spare space in the embedded device and recompiling the qemu backend code with llvm (??!!) and running it through their symbolic execution framework and syncing that state all over and... basically I had no idea what was going on but it was wonderous. No serious issues found in a Nokia 3310 yet, though.
- LLVM Linux: The kernel and gcc have grown together, and hence the kernel gets away with all kinds of awful things that llvm just outright refuses to add support for. The guy was amazingly angry about a tiny bit of C that gcc supports (badly), named VLAIS. It's in some of the crypto code in the kernel that gets copy-pasted between modules. This was far more horrifying to me.
- Power management: A system wide challenge: Hardware engineers are really smart and like to show it with maths and clock gating. Understood some interesting things; e.g. it's worth shipping one high-nm/high-bin core (to run at a lower power and a lower frequency more of the time), and loads of low-nm/low-bin cores to run fast and loose. Power usage is related to the frequency cubed.
- Helgrind for Valgrind: Let's re-interpret concurrency as a graph. It doesn't really matter what you were trying to do with your locks; just the presence of a lock or unlock implies that you meant to do something. Add a graph edge to nearby other uses of that lock. Other edges are time on the same thread. Dominators. Bam, done. Then they optimised it with vector clocks, which I thought I'd escaped when it became acceptable to only understand Raft, not the other horror.
- Capsicum: Capabilities are a good way to do things. Allows applications to drop arbitary privileges, i.e. "don't let me make any directories I've currently got open for reading writable, or let me do anything scary to the network card".
tcpdump as an example, which was nicely real-world. Good slides comparing the other options on Linux and other OSes for sandboxing (e.g. Chromium).
- No more IPv4: A review of loads of stuff that would have been useful to know for the previously mentioned argument, that we had to learn from the horrors of wikipedia and nearby Cisco employees.
- Software Transactional Memory: Might help you write better code (declarative instead of imperative concurrency), and what looked like a declarative distributed transaction manager, which I completely failed to understand in any way.
9/10 would attend again.
2013-05-18
xqillac is a fork of the xqilla command-line XQuery processor to.. make it work better from the command line. XQuery is a language for searching and editing XML; a superset of XPath.
For example, let's say you have some XML coming along a shell pipeline:
<a>
<b id="5">hello</b>
<b id="7">world</b>
</a>
..and you want just the 5th b's text:
$ printf '<a><b id="5">hello</b><b id="7">world</b></a>' |
xqilla -i /dev/stdin <(echo "data(//b[@id='5'])")
hello
Groovy. Much safer than trying to do this kind of thing with regexes or cut or whatever.
However, as you can see, this involves horrible abuse of the shell "<(" operator (which turns a command's output into a file (..well, close enough, right?)), and of /dev/stdin.
In xqillac, this is just:
printf '<a><b id="5">hello</b><b id="7">world</b></a>' |
xqillac "data(//b[@id='5'])"
The above shell hack also fails (horribly: "Caught unknown exception"... or worse) if you attempt to use XQuery Update to edit the document in the pipeline:
xqillac allows this (for documents that fit in memory):
$ printf '<a><b id="5">hello</b><b id="7">world</b></a>' |
xqillac "delete nodes //b[@id='5']"
<a><b id="7">world</b></a>
Code on xqillac's github. Please use the Github functionality for issues and pull requests.
Continue reading...
2013-05-18
I like StatCounter's browser usage statistics, even if there are outstanding arguments about how they deal with data from multiple countries (i.e. if you're using them for decisions, you're probably much better taking the stats for your target country, rather than the global or regional stats... but you'd probably be doing that anyway.)
I dislike, however, the way they handle browser versions. I have always thought that they have more data than they display, and do a very poor job of actually showing it to you. For example, the Browser Versions for the time of writing has, at one point, 60+% of browsers in "uncategorised". How does that even happen?!
Browser Version (Partially Combined) makes a better stab at useful information, but is still lacking so much.
So... I wrote my own. Click for a full view:

This picks out some reasonably interesting features:
- The huge black wedge between 2010-02 and 2011-04, in the Firefox area, is Firefox 3.6. You can see it absolutely refusing to die for the following few years, despite people using more modern versions.
- The relentless Chrome release schedule.
- How long of a tail IE has on releases being picked up by users, and how IE10 is doing better (automatic updates, perhaps?)
This is generated by browserstats. Yes, that has a lot of data archived from StatCounter. Yes, the code is awful and it's a pretty manual process to update the graph. Feel free to fix it.
2013-05-18
(I've been saving up a load of tiny projects for one mega blog post. Apparently that's not working. Small project avalanche!)
foo_disccache (possibly more correctly spelt foo_diskcache) is a small foobar2000 component to help smooth playback on machines with plenty of memory.
It tries to trick the OS into caching some of the files that are soon to be played, so playback won't need to stall (waiting for the disc) when the track comes to play. This additionally allows the drive the music is being read from to spin down (saving noise/power) more frequently, and will assist with uninterrupted music playback when the system is under heavy IO load.
If you don't understand any of that, you almost certainly don't care.
Download and installation instructions are at Github. Please use Github's issue tracker or wiki for discussion, not comments.
2012-09-05
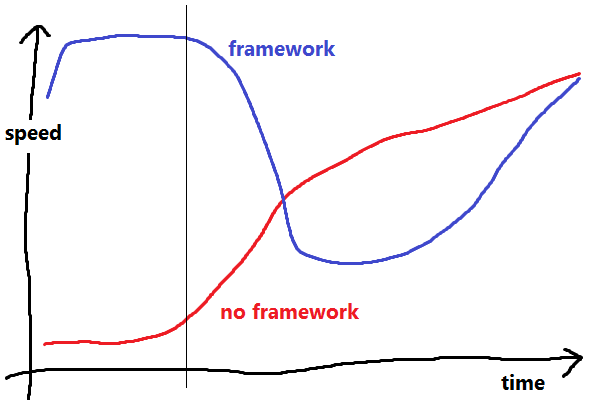
In his Serious Beard Talk, delivered at DjangoCon 2008, Cal Henderson explains how he thinks frameworks affect productivity. I would like to bring it up again, because it's still as relevant as ever, and it's hard to link busy software engineers to YouTube videos (of things that aren't cats).
A framework (or library?) exists to save you from doing common, repetitive tasks (he's thinking of things like mapping URIs to places, and reading and writing entities to the database) by providing a bunch of pre-existing code that'll do all this stuff for you:
- If you decide to write all this stuff from scratch, you're going to be spending a lot of time developing boring, repetitive code (but maybe you're still doing it better than other people?), and you're not going to be delivering anything fancy. Eventually, though, you'll get up to speed, and your well-understood, targeted framework/library will assist you in every way.
- If you pick the framework route, it takes you a short amount of time to get one of the damn demos to start, then you get a whole load of stuff for free, but, eventually, you run into things the framework can't or won't do for you, and you have to work out how to ram your workflow down its stupid throat aargh. Your delivery speed plummets, but eventually you'll get it working, and you'll have some free good design and code reuse in there. Now, with a decent grounding in how the framework works, and your extra flexibility layer, you can get back to the good stuff.
This results in roughly The Framework Graph, shown here, reproduced (in Paint) without permission.
I believe an unawareness of this Graph comes up frequently, even when not discussing frameworks directly:
- I don't want to use a big complex library, it'll be simpler to do it myself.
- I can't get it to do quite what I want, I'll start again from scratch.
- I don't really understand why it makes this operation so hard, the tool must be broken. (Hibernate, anyone?)
- Why does it want all those parameters/config/values? I just want it to work.
I can pick many examples from my non-professional experience has come up, my favourite is (coincidentally!) That Graph Drawing Code:
This may not sound like a framework choice on the scale that he's talking about, but I urge you to consider the sheer horror of that PHP code.
In summary: The big horrible library/framework/tool/etc. will almost certainly provide you with more total productivity in the short (when most projects fail, at about the vertical line on the Graph), medium and long term, regardless of any pain it gives you.
2012-06-06
In light of today's supposed LinkedIn breach, it seems like an appropriate time to finally write up my password policy.
Many people have cottoned on to the idea that having the same password on different sites is a bad idea. There's various technical solutions to this, such as generating a site-specific password. I, however, believe this scheme to be too inconvenient; they require you to always have access to the site or tool, and don't work well in public places.
What we're really trying to do here is:
- Have different passwords on different sites.
- Have passwords that are (very) hard to guess.
- Be as lazy as possible.
What the first means is: If an attacker is given my password for a specific site, they can't easily derive the password for any other site. I am willing to risk the chance of them retrieving the password for multiple sites.
My proposal is to have a way to generate secure, site-specific passwords in one's head:
- Remember an excessively long password.
- Come up with some way to obscure the site name.
- Put the obscured site name in the middle of your long password, and use that password for the site.
That is:
- Remember an excessively long password: 14 characters is a good start. (My) pwgen can help you come up with suggestions. Note that this password doesn't need to be full of capitals, numbers or symbols; the sheer length makes it secure. "
c8physeVetersb" is around a thousand times "more secure" (higher entropy) than "A0Tv|6&m".
- Come up with a set of rules to obscure the site name: For example, take the "letter in the alphabet after the first character of the site name", and "the last character of the site name, in upper case". e.g. for "amazon", the obscured version of the site name would be "
bN".
- Mix them together: e.g. I'm going to insert the first bit,
'b' after the 'V', and the second bit, 'N' after the last 's', giving me "c8physeVbestersNb".
- Use this password on Amazon.
Even if Amazon are broken into, all the attacker will get (after many CPU-decades of password cracking), will be "caphyseVbester5Nb", which, even if they know you're using this password scheme (but not the details of your transformation), doesn't tell them anything about your password on any other site.
All you have to do is remember the alphabet (uh oh).
Continue reading...
« Prev
-
Next »
{kind=link}
{kind=link}